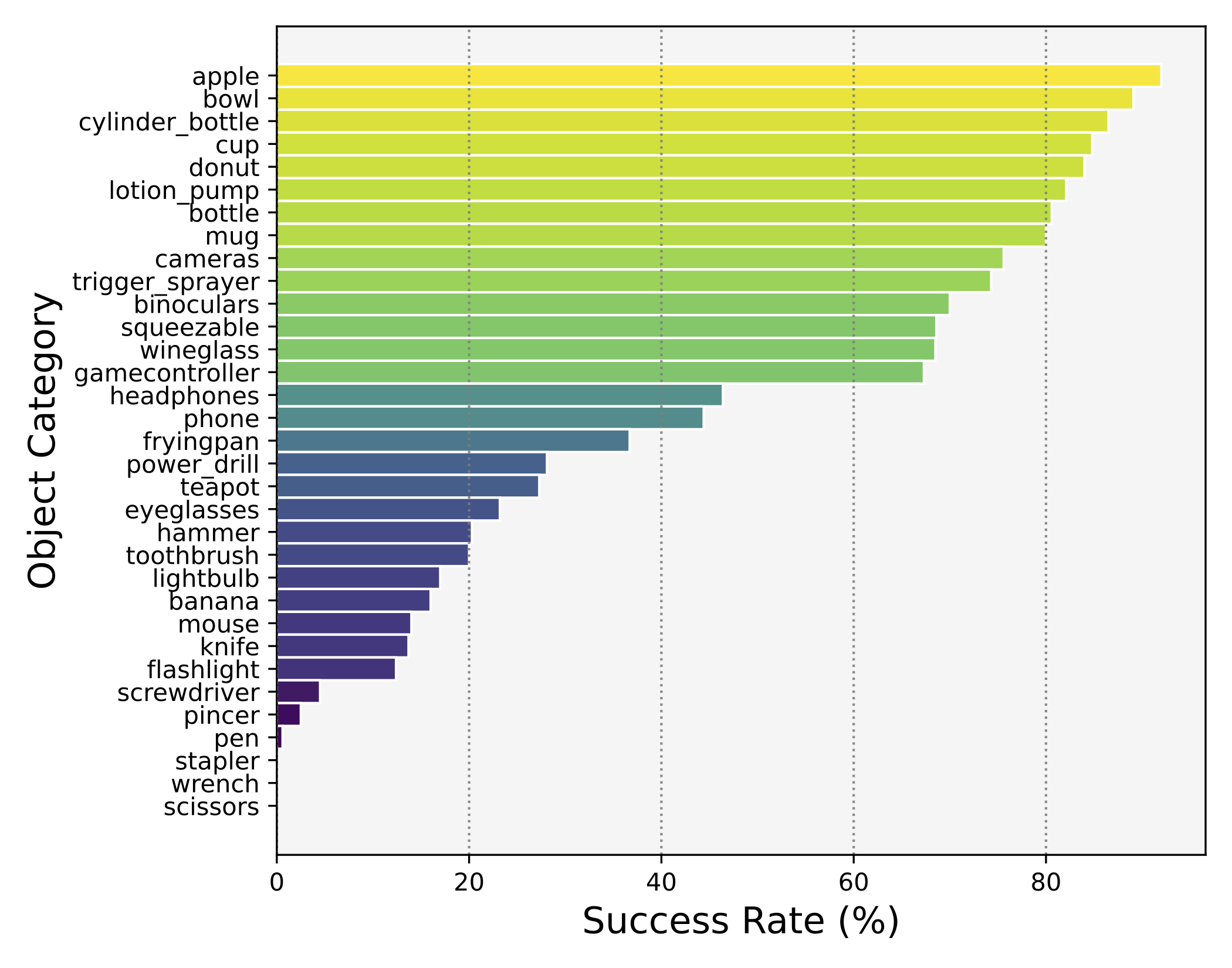
In real-world scenarios, objects often require repositioning and reorientation before they can be grasped, a process known as pre-grasp manipulation. Learning universal dexterous functional pre-grasp manipulation requires precise control over the relative position, orientation, and contact between the hand and object while generalizing to diverse dynamic scenarios with varying objects and goal poses. To address this challenge, we propose a teacher-student learning approach that utilizes a novel mutual reward, incentivizing agents to optimize three key criteria jointly. Additionally, we introduce a pipeline that employs a mixture-of-experts strategy to learn diverse manipulation policies, followed by a diffusion policy to capture complex action distributions from these experts. Our method achieves a success rate of 72.6% across more than 30 object categories by leveraging extrinsic dexterity and adjusting from feedback.

Extrinsic Dexterity Usage: Our policy leverages the table and inertia to aid in manipulating objects.

Adaptability: Although our policy may initially fail to manipulate objects, it adjusts its policy on the second attempt, successfully manipulating them.
While our method achieves a high success rate across the entire dataset, it still struggles with irregularly shaped objects, particularly thin and slender ones like knives and pens.